|
I am a third-year PhD student at College of Electronic Information and Engineering, Tongji University and Department of Computer Science, Tsinghua University, advised by Prof.Fuchun Sun. I obtained my B.S. and M.S at Beihang University. My research interest lies in the 3D/4D Generation, Video Generation, and 3D Reconstruction. I am particularly interested in combining video diffusion model with sequential 3D generation methods. |

|
|
|
-
2025-03:
- New 4D-Generation Work Video4DGen Accepted by IEEE TPAMI.
- Work about Non-rigid Point Cloud Shape Correspondence Accepted by IEEE TIP.
-
2025-01:
- Work about Physics-enhanced NeRF Accepted by IEEE Sensors Journal.
- New Open Source 3D-Generation Project: Tencent Hunyuan3D-2.0.
|
* indicates equal contribution |
|
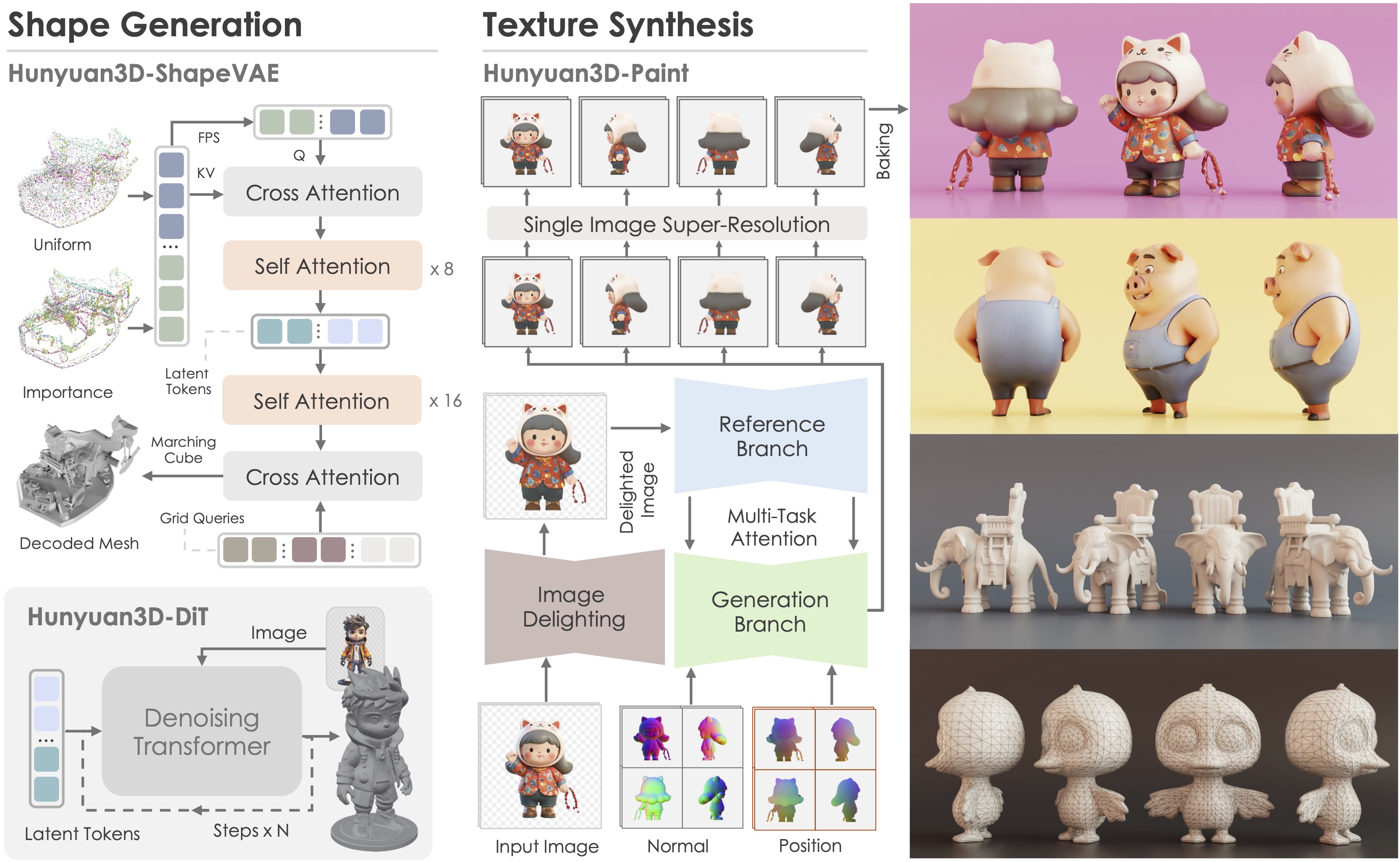
Hunyuan-3D Team Github, 2025 [PDF] [Code] [Project Page] We propose Tencent Hunyuan3D-2.0, a unified framework for text-to-3D and image-to-3D generation. |
|
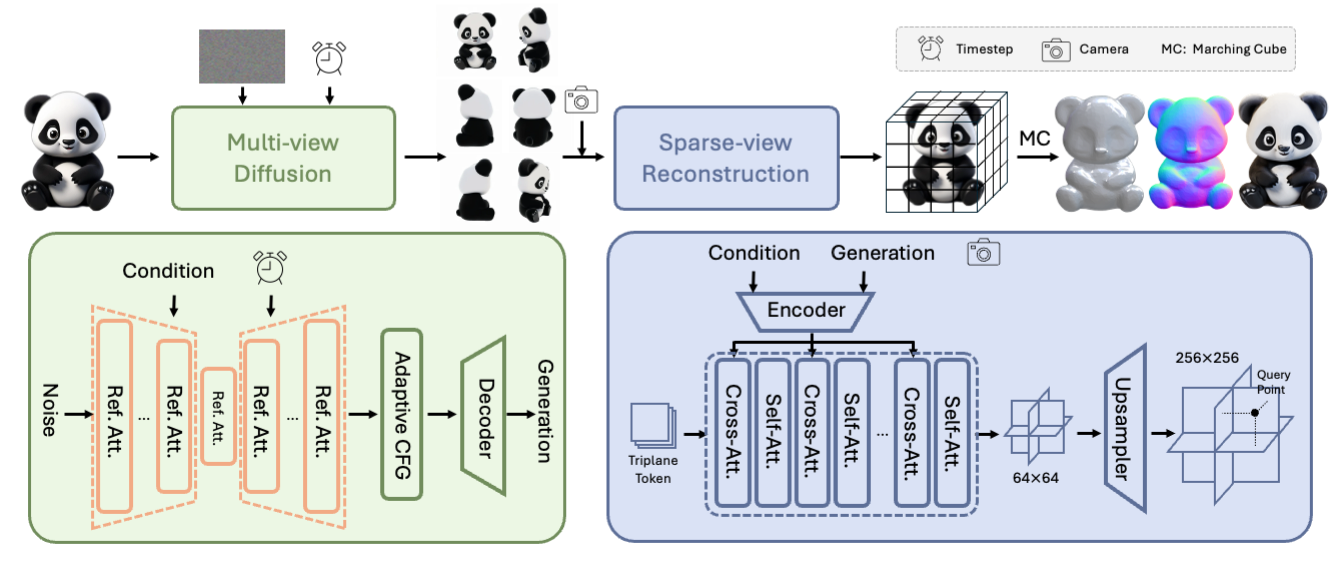
Xianghui Yang, Huiwen Shi, Bowen Zhang, Fan Yang, Jiacheng Wang, Hongxu Zhao, Xinhai Liu, Xinzhou Wang, Qingxiang Lin, Jiaao Yu, Lifu Wang, Zhuo Chen, Sicong Liu, Yuhong Liu, Yong Yang, Di Wang, Jie Jiang, Chunchao Guo Arxiv, 2024 [arXiv] [Code] [Project Page] We propose Tencent Hunyuan3D-1.0, a unified framework for text-to-3D and image-to-3D generation. |
|
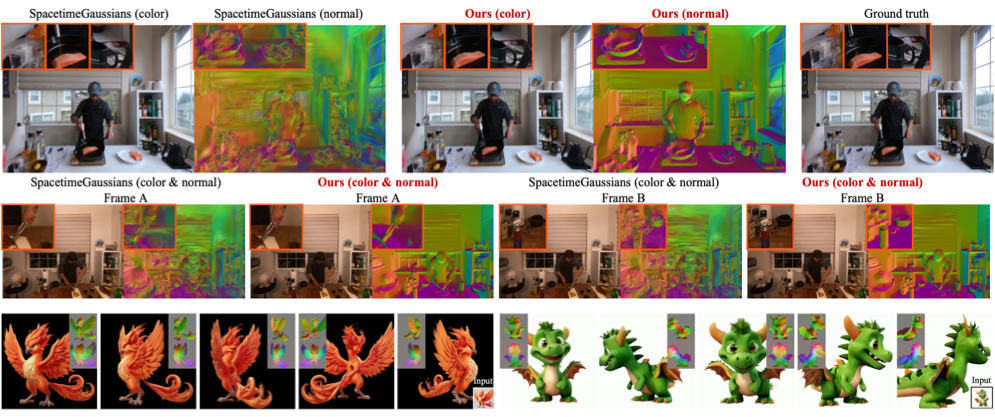
Yikai Wang, Guangce Liu, Xinzhou Wang, Zilong Chen, Jiafang Li, Xin Liang, Fuchun Sun, Jun Zhu. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 [Code] We propose a multi-view video generation method with 3DGS. |
|
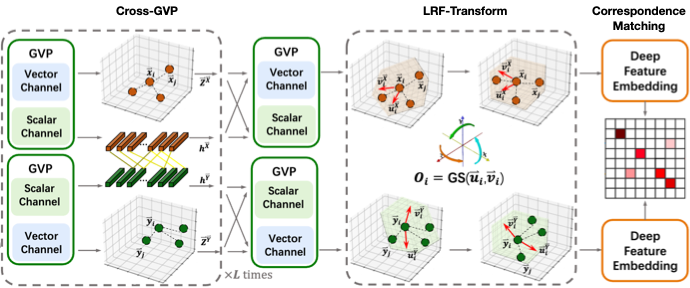
Ling Wang, Runfa Chen, Yikai Wang, Fuchun Sun, Xinzhou Wang, Sun Kai, Guangyuan Fu, Jianwei Zhang, Wenbing Huang IEEE Transactions on Image Processing (TIP), 2025 [arXiv] We present a framework for unsupervised non-rigid point cloud shape correspondence registration, incorporating principles of equivariance. |
|
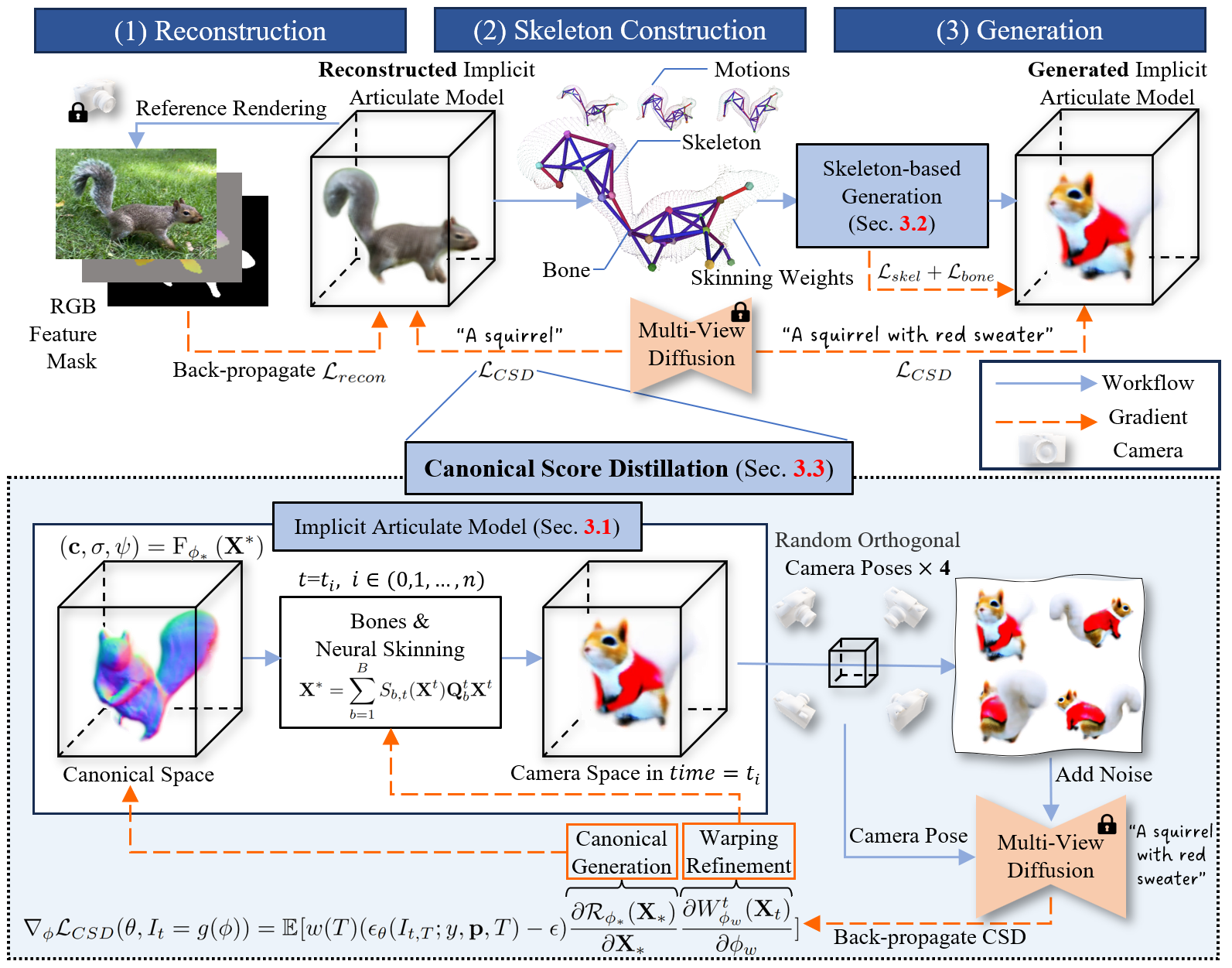
Xinzhou Wang, Yikai Wang, Junliang Ye, Zhengyi Wang, Fuchun Sun, Pengkun Liu, Ling Wang, Kai Sun, Xintong Wang, Bin He ECCV, 2024 [arXiv] [Code] [Project Page] We propose AnimatableDreamer, a framework with the capability to generate generic categories of non-rigid 3D models. |
|
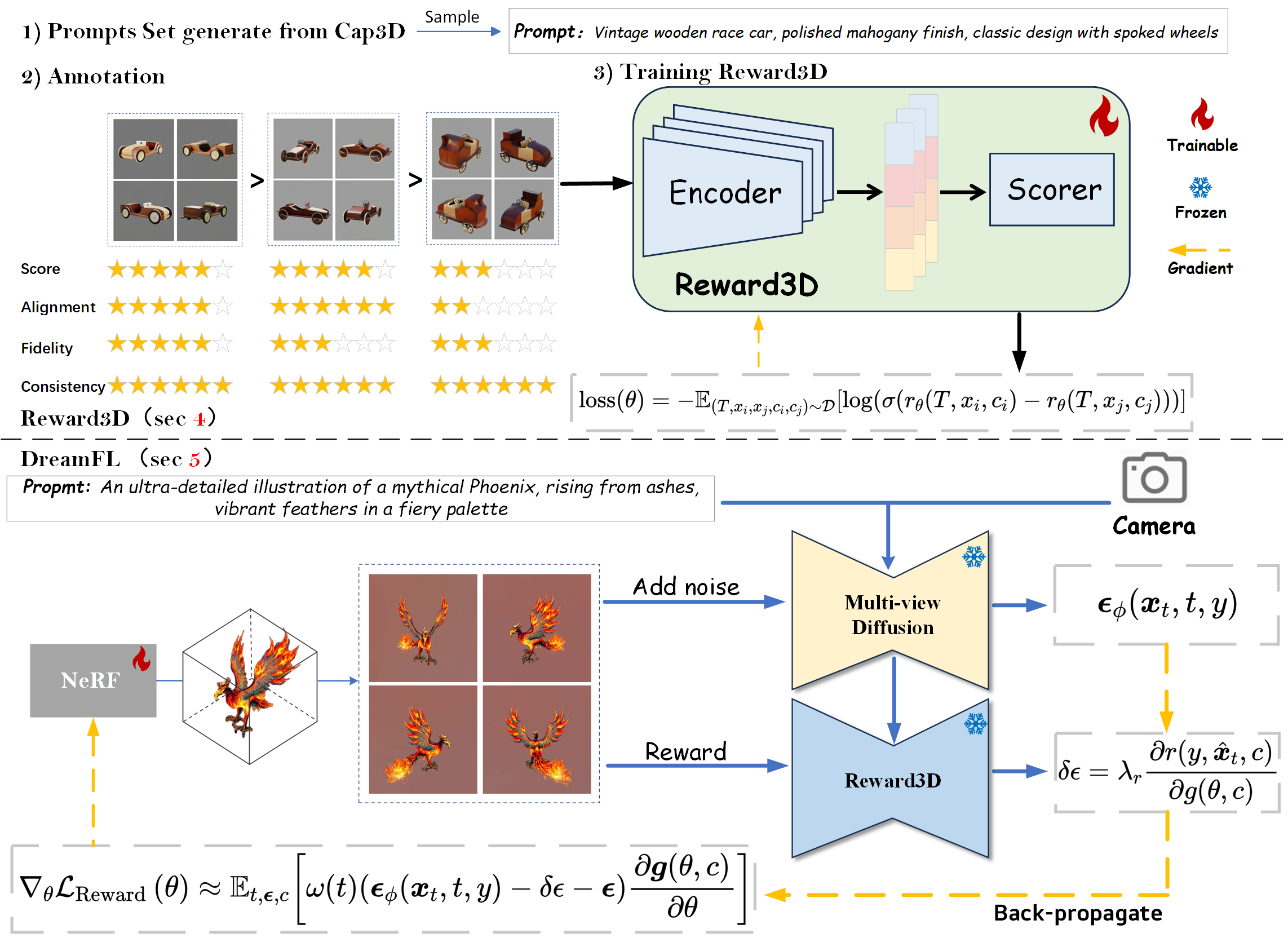
Junliang Ye*, Fangfu Liu*, Qixiu Li, Zhengyi Wang, Yikai Wang, Xinzhou Wang, Yueqi Duan , Jun Zhu ECCV, 2024 [arXiv] [Code] [Project Page] We present a comprehensive framework, coined DreamReward, to learn and improve text-to-3D models from human preference feedback. |
|
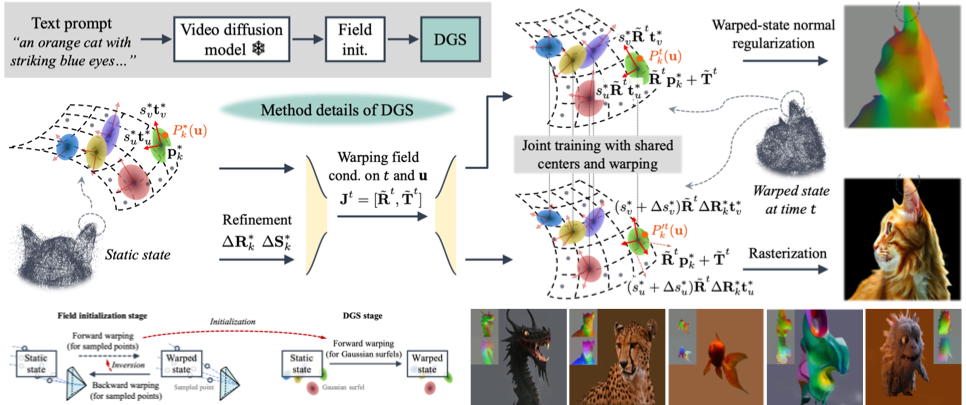
Yikai Wang*, Xinzhou Wang*, Zilong Chen, Zhengyi Wang, Fuchun Sun, Jun Zhu NeurIPS, 2024 [arXiv] [Code] [Project Page] [Youtube] We present a Vidu4D, a framework to reconstruct high-fidelity 4D model from generated videos. |
|
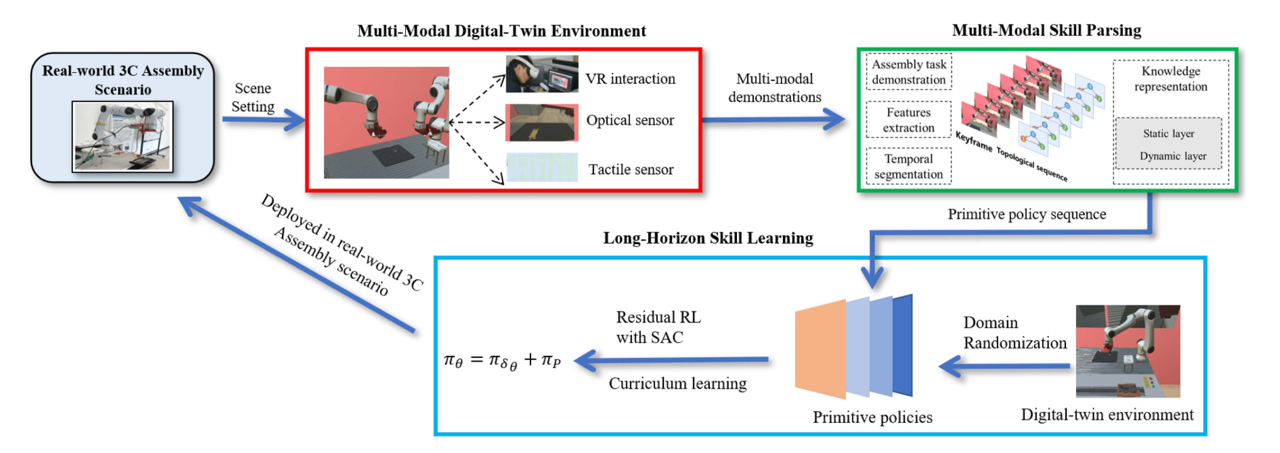
Fuchun Sun, Naijun Liu, Xinzhou Wang, Ruize Sun, Shengyi Miao, Zengxin Kang, Bin Fang, Huaping Liu, Yongjia Zhao, Haiming Huang IEEE Transactions on Cybernetics. [paper] We present a digital twin with reinforce learning for sim-to-real 3C assembly task. |
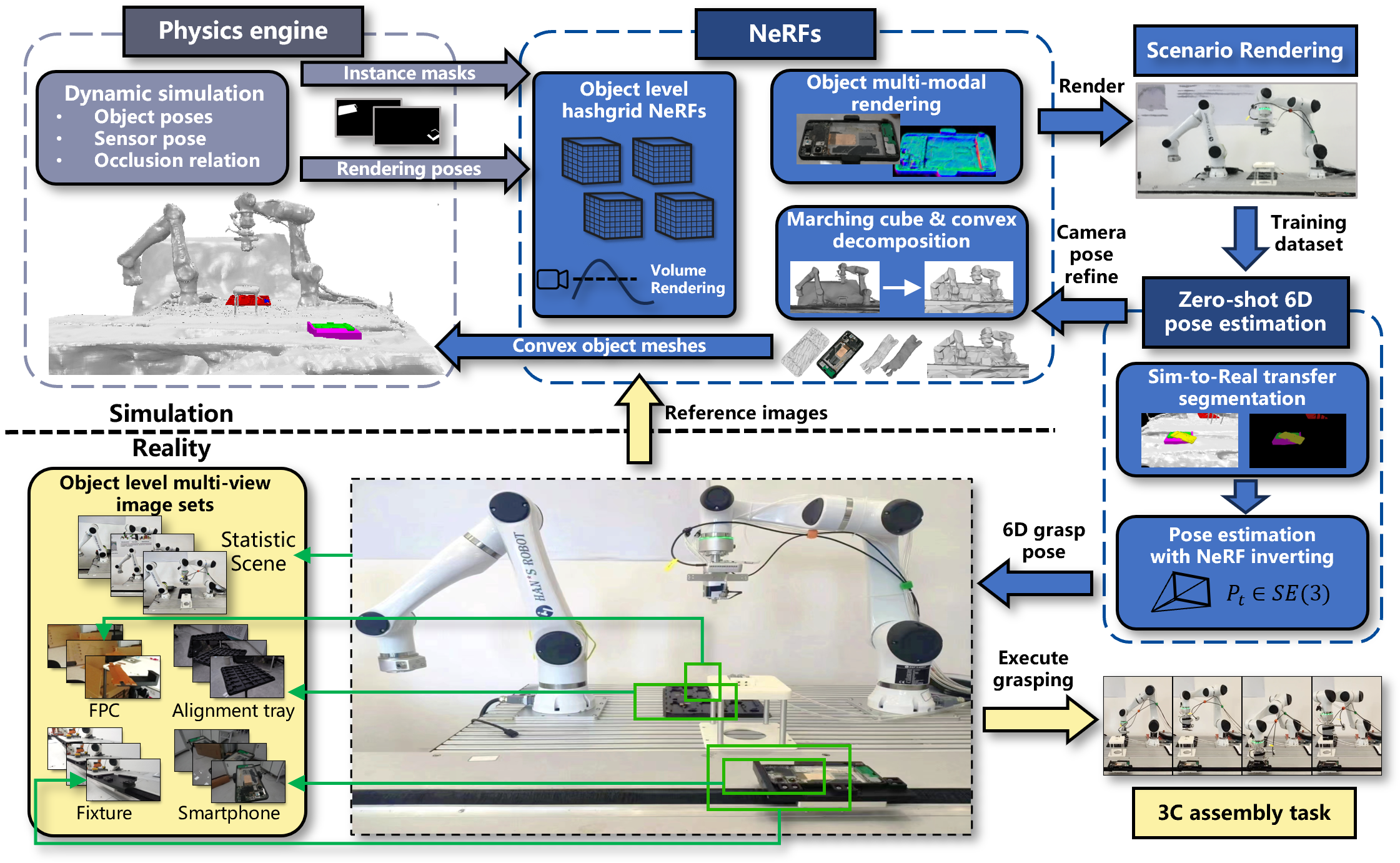
|
Xinzhou Wang, Fuchun Sun, Ling Wang, Kai Sun, Yuanyan Xie, Xintong Wang, Bin He, Huaidong Zhou IEEE Sensors Journal [arXiv] We present a implict digital twin with physics engine for sim-to-real 3C assembly task. |
|
Pengkun Liu, Yikai Wang, Fuchun Sun, Jiafang Li, Hang Xiao, Hongxiang Xue, Xinzhou Wang Arxiv, 2024 [arXiv] [Code] [Project Page] We propose Isotropic3D, an image-to-3D generation pipeline that takes only an image CLIP embedding as input. |
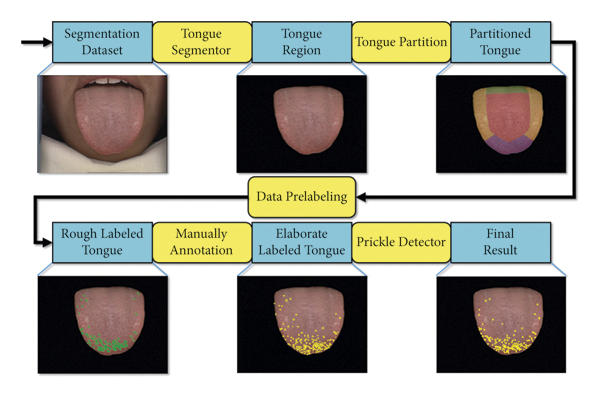
|
Xinzhou Wang, Siyan Luo, Guihua Tian, Xiangrong Rao, Bin He, Fuchun Sun Evidence-Based Complementary and Alternative Medicine, 2022 [Paper] We provides a quantitative perspective for symptoms and disease diagnosis according to tongue characteristics. |
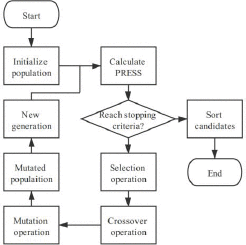
|
Xintong Wang, Xinzhou Wang International Conference on Algorithms, Data Mining, and Information Technology (ADMIT), 2022 [Paper] We provides a method for measurement selection of Aero-engine gas path analysis. |
|
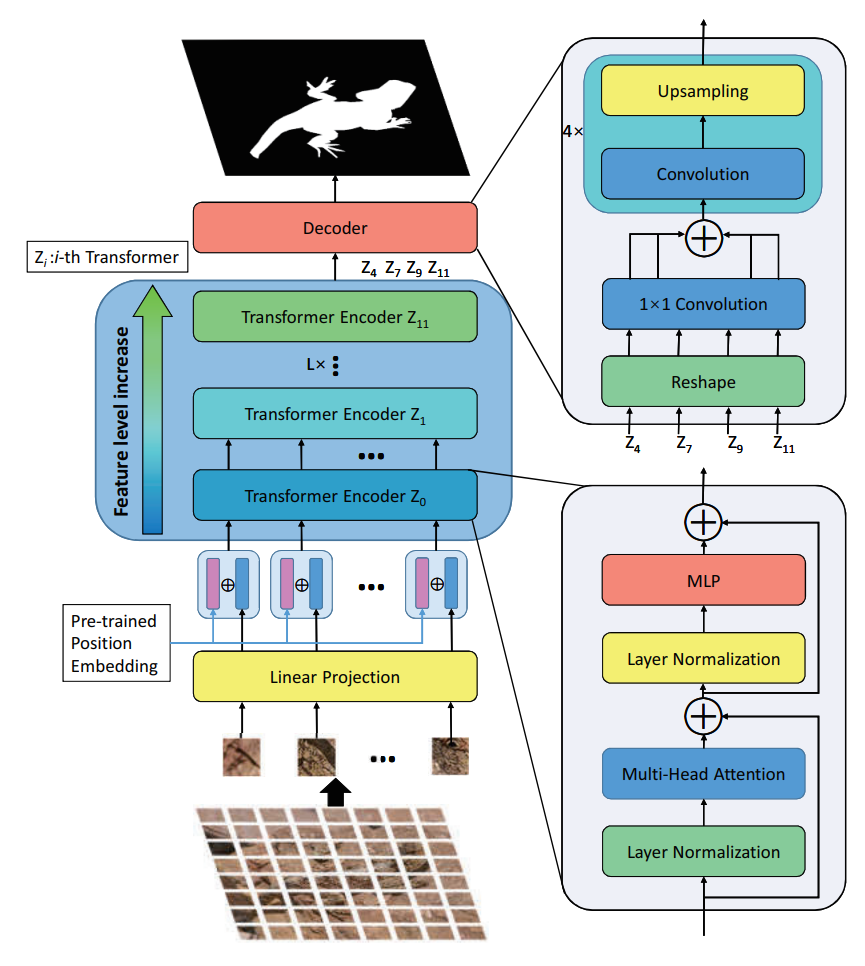
Haiwen Wang*, Xinzhou Wang*, Fuchun Sun, Yixu Song Cognitive Systems and Information Processing, 2021 [Paper] We provides a transformer for camouflaged object segmentation. |
|
|